LTX Video
Core Features
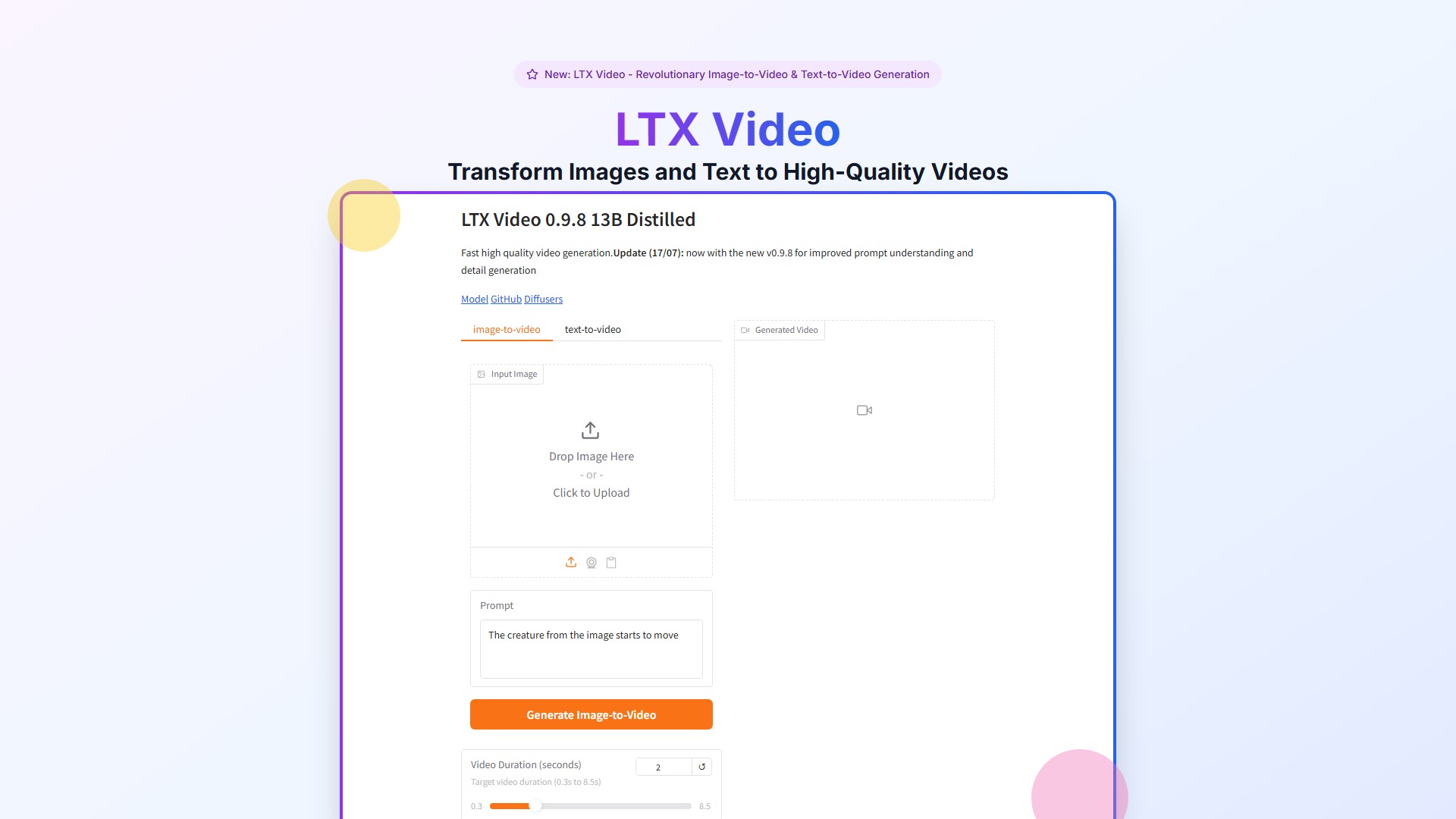
- Image-to-Video Generation: Transform static images into dynamic video content
- Text-to-Video Creation: Generate high-quality videos from text descriptions
- DiT Architecture Processing: Utilizes innovative Diffusion Transformer technology
- High-Resolution Output: Create 768p resolution videos at 24 FPS with up to 5 seconds duration
Technical Features
- Temporal Consistency: Ensures smooth transitions between video frames
- Dual-Mode Generation: Supports both image and text inputs
- Open-Source Platform: Complete model available on Hugging Face and GitHub
- Fast Processing: DiT architecture enables efficient video generation
Workflow
- Input Content: Upload images or enter text descriptions
- DiT Processing: Analyze input and plan video generation
- Video Generation: Create high-quality video content
- Download & Use: Obtain generated videos for projects
Pricing Plans
- Open Source Free Access: Model access, example code, community support
- Developer Access (Coming Soon): API access, advanced features, priority processing, commercial license
- Enterprise Custom: Custom deployment, white-label solutions, dedicated support
Target Users
- Content creators and video producers
- AI researchers and developers
- Enterprise video production teams
- Educational and research institutions
Core Advantages
- Advanced DiT architecture ensures video quality
- Open-source model facilitates research and development
- Multiple input methods provide creative flexibility
- Professional-grade output quality meets commercial needs
가격 모델:
Contact for Pricing
Free
Paid
의론