Stable Diffusion 3 AI Image Generator Free Online
Main Features
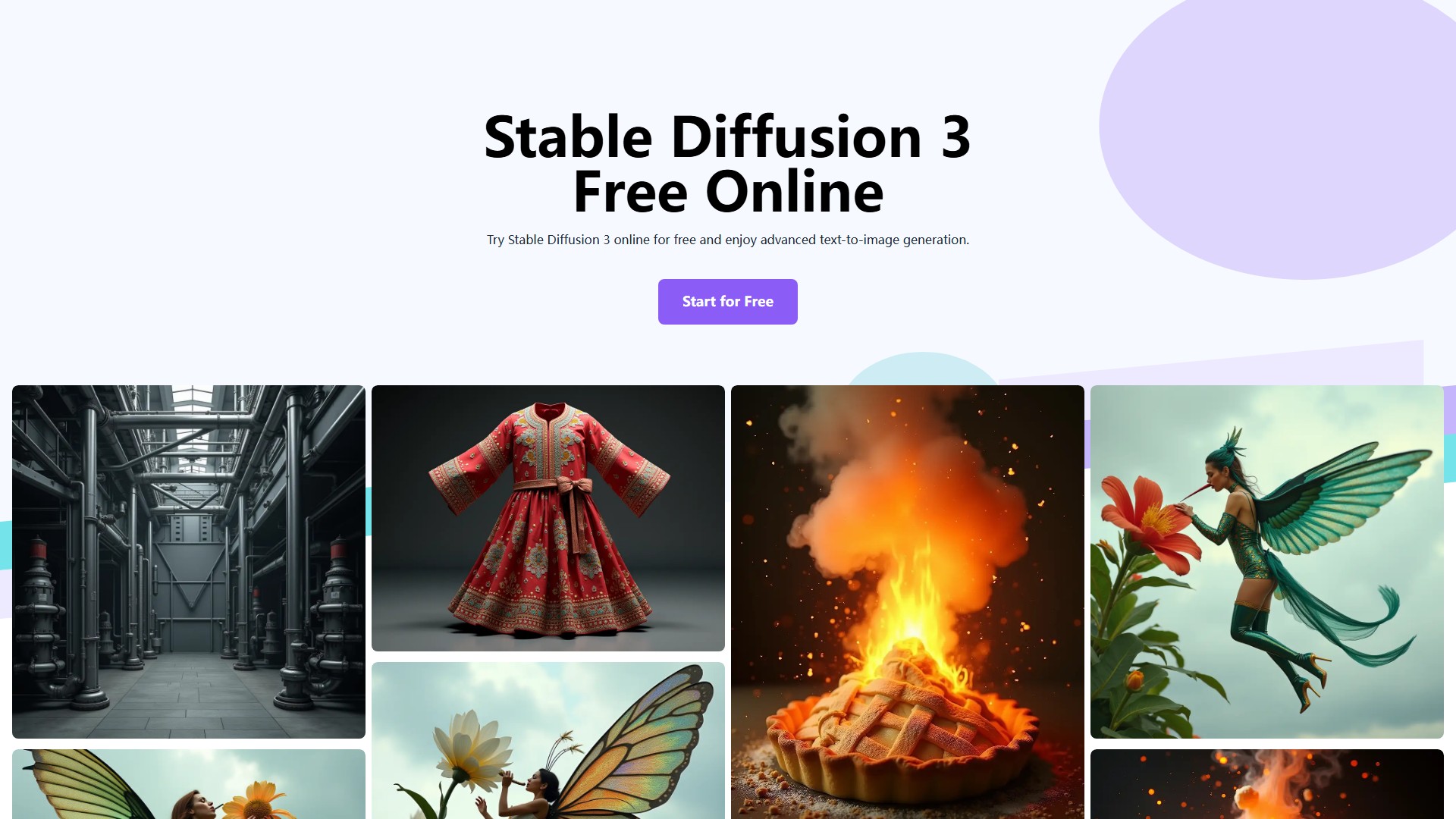
- Text-to-Image Generation: Generates high-quality images from text prompts.
- Improved Text Generation: Capable of producing legible and coherent text within images.
- Better Prompt Following: Generated images closely match the described content, subjects, and styles.
- Multi-Subject Handling: Excellently handles prompts with multiple distinct subjects, producing high-quality images.
- Advanced Architecture: Utilizes the new Multimodal Diffusion Transformer (MMDiT) architecture, featuring separate weights for image and language representations, with model sizes ranging from 800M to 8B parameters.
Core Advantages
- Superior Image Quality: Outperforms other state-of-the-art models, especially in typography and prompt adherence.
- Free Access: stablediffusion3.net provides a free quota for users to experience its features at no cost.
- Flexible Deployment Options: Offers various access methods including API, self-hosting (with a Stability AI Membership), and online platform usage.
- Robust Safety Measures: Emphasizes strong safety practices to prevent misuse and ensure ethical AI deployment.
How to Use
- Register for Free: Sign up on the website to receive a free usage quota.
- Enter Your Prompt: Input a text prompt into the provided interface to leverage the Stable Diffusion 3 weights for image generation.
- Download Your Images: Once the AI generates the images, you can download them.
Who Can Benefit
- Graphic Designers: For creating high-quality visual works.
- Content Marketers: To generate engaging visuals that align with content strategies.
- Software Developers: To integrate advanced text-to-image generation capabilities into their applications via the API.
- Educators: For creating educational materials and visual aids.
- Advertising Agencies: To produce high-quality advertisements and promotional materials.
- Researchers: To analyze and visualize complex data using its advanced image generation capabilities.
How It Works
Stable Diffusion 3 leverages the Diffusion Transformer (DiT) architecture, integrating advanced noise predictors and sampling techniques to produce high-quality images. The model uses distinct weights for image and language representations, ensuring precise and coherent text generation within images. Users input text prompts via the API, which the model converts into detailed and accurate images.
Frequently Asked Questions (FAQ)
- What is the stable diffusion 3 release date?
- What are the benefits of using the stable diffusion 3 API?
- What are the differences between stable diffusion 3 vs SDXL?
- Where can I find stable diffusion 3 online resources and documentation?
- How does the stable diffusion 3 architecture differ from previous versions?
- Can I customize the stable diffusion 3 weights for specific applications?
価格設定モデル:
Freemium
Free Trial
議論する