Voicv
Main Functions
- Voice Cloning: Create an exact digital replica of your voice with just 10-30 seconds of audio sample, maintaining high fidelity and natural expression
- Text to Speech: Convert written content into natural-sounding speech with customizable voices
- Speech to Text: Accurately transcribe audio recordings into text in seconds
Key Features
- Zero-Shot Voice Cloning: Clone any voice with just a short audio sample
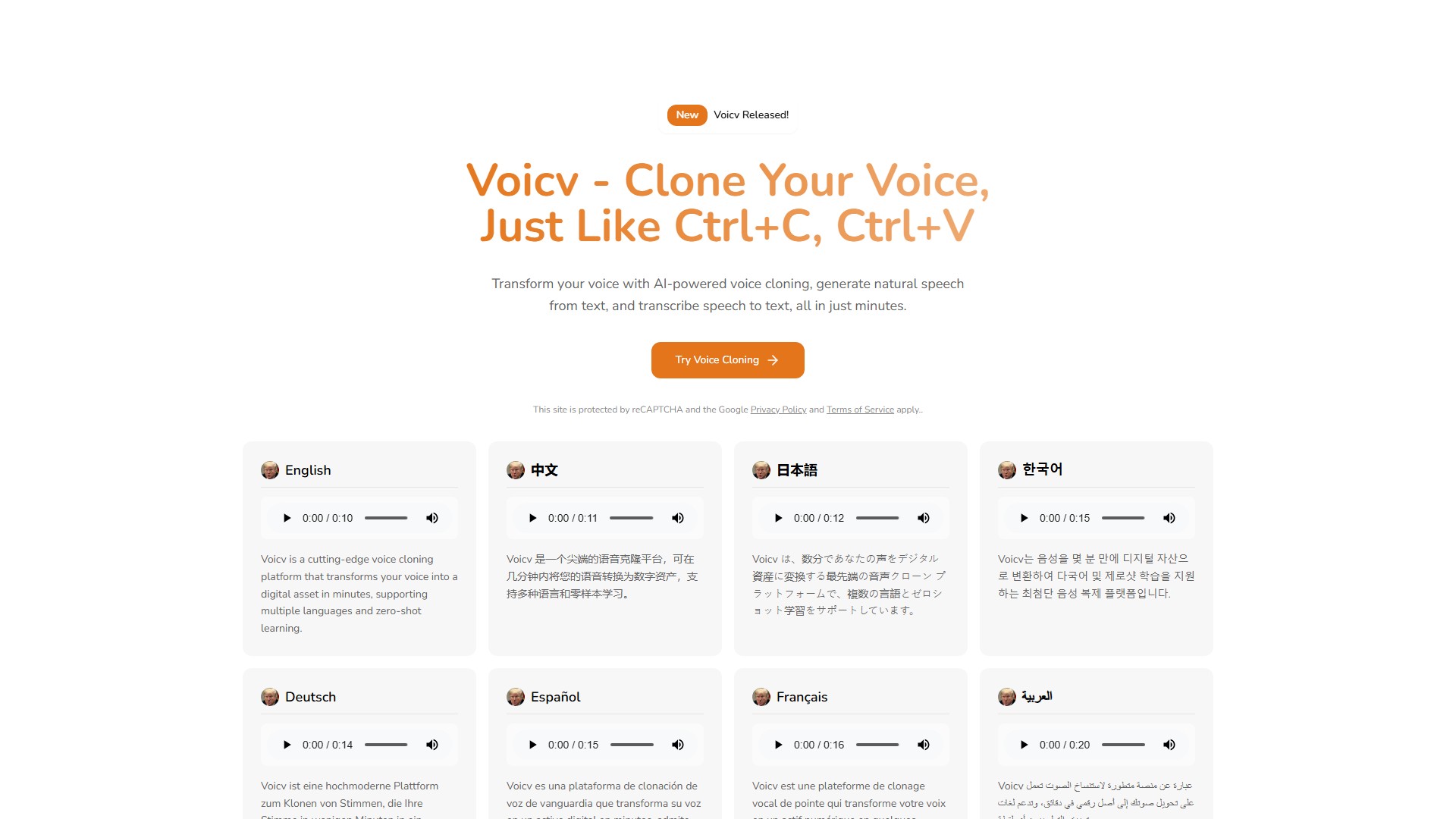
- Multilingual Support: Generate speech in English, Japanese, Korean, Chinese, French, German, Arabic, and Spanish
- Real-Time Processing: Fast voice generation with optimized engine
- High Accuracy: Extremely low error rates for clear and accurate speech generation
- Emotion Control: Support for pauses, breaths, and laughter control for more expressive and natural speech
- Enterprise-Ready: Production-ready API with comprehensive documentation
Target Users
- Content creators
- Podcasters
- Businesses seeking consistent brand voice development
- Professional voice actors
- Users with speech disabilities
Use Cases
- Multilingual content creation
- Audiobook production
- E-learning materials
- Accessibility solutions
- Meeting notes
- Content repurposing
- Podcast localization
User Feedback
Users report excellent performance in content creation workflow, multilingual dubbing, emotional expression capture, and ethical security.
Pricing Mode:
Contact for Pricing
Comment