ImageBind
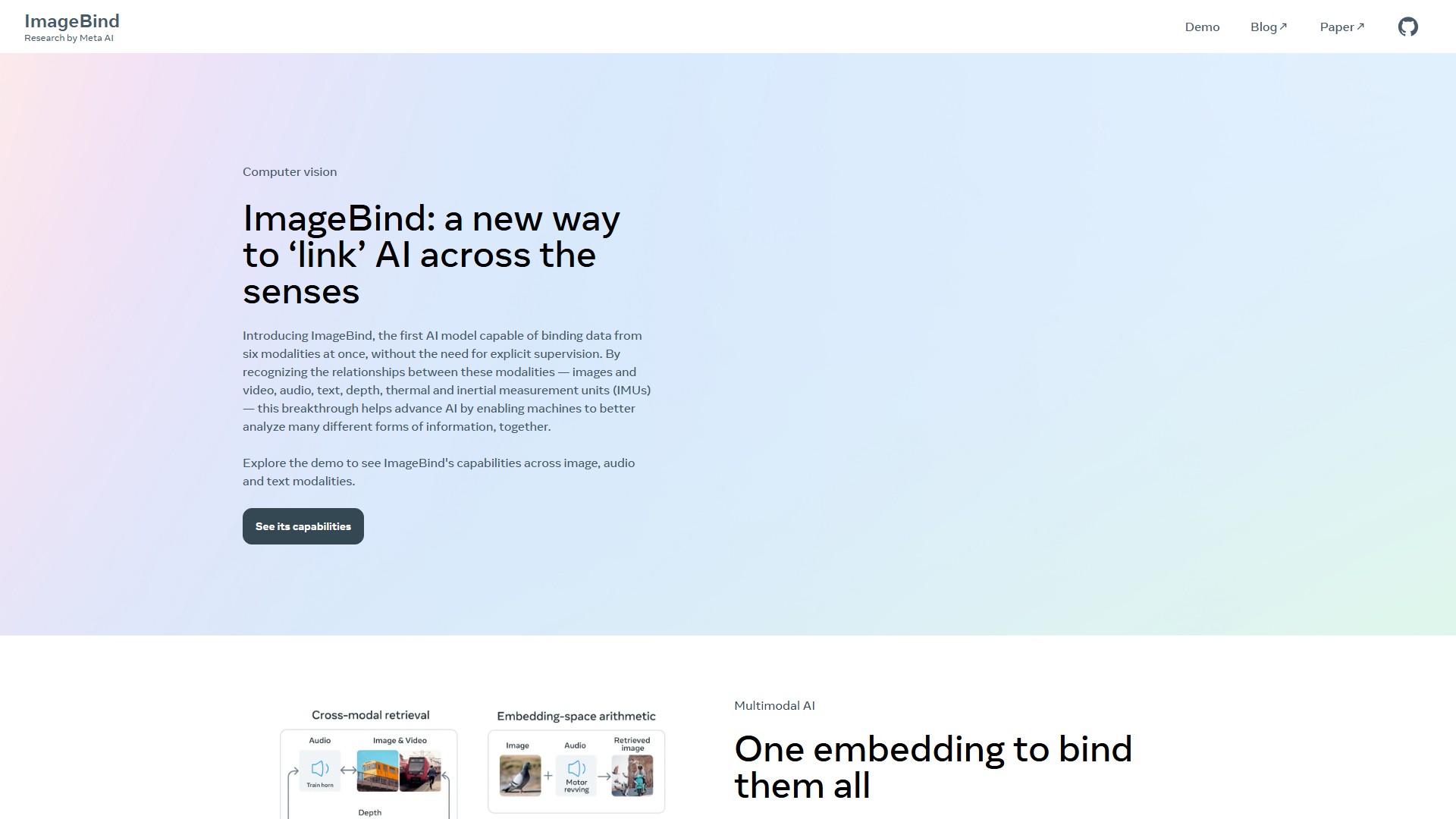
主要功能:ImageBind是首个能够在无需显式监督的情况下,一次性绑定来自六种模态(图像与视频、音频、文本、深度、热成像和惯性测量单元IMUs)数据的AI模型。通过学习单一的嵌入空间将多种感官输入绑定在一起,该模型能够升级现有AI模型以支持这六种模态中的任何输入,从而实现基于音频的搜索、跨模态搜索、多模态算术和跨模态生成。
核心优势:具备突破性的跨模态关系识别能力,使机器能够更好地综合分析多种不同形式的信息。开源的ImageBind模型在跨模态的涌现零样本识别任务上实现了新的SOTA(最先进)性能,甚至优于专门针对这些模态训练的先前专业模型。同时支持零样本和少样本识别。
使用说明:用户可以通过网站的Demo页面探索ImageBind在图像、音频和文本模态上的能力。开发人员可以通过GitHub获取开源代码进行集成和开发。
其他信息:该模型及代码为开源提供,页面未提及收费模式与价格信息。
访问量:
24.4K
国家:
United States
计价模式:
Contact for Pricing
评论