ControlNet Pose
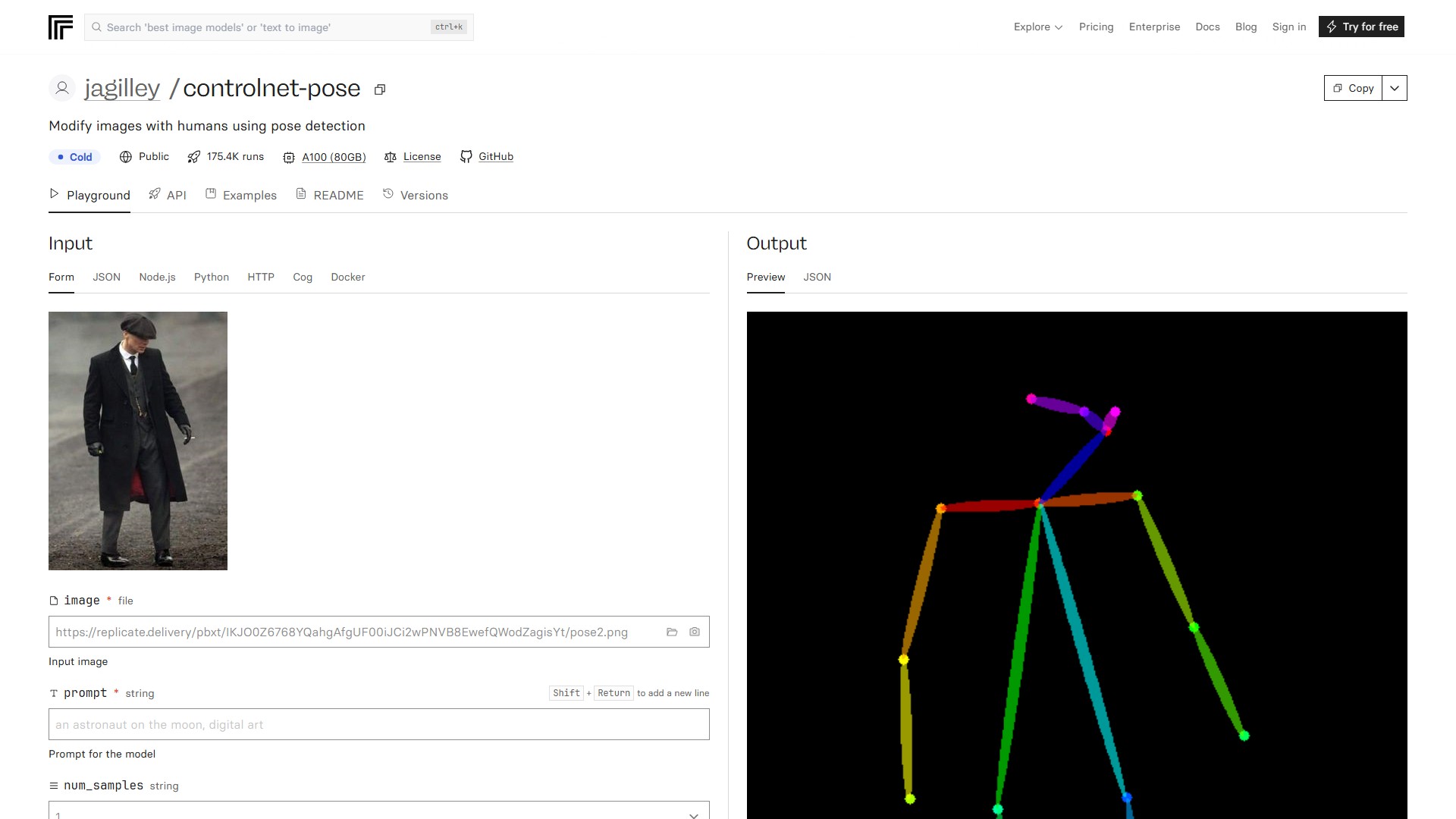
主要功能:jagilley/controlnet-pose模型用于通过人体姿势检测来修改图像。输入一张图像和文本提示,模型将使用Openpose检测姿势,并结合提示生成输出图像。
模型描述:ControlNet是一种神经网络结构,允许控制预训练的大型扩散模型以支持提示之外的附加输入条件。即使训练数据集较小(<50k样本),ControlNet也能以端到端的方式学习任务特定条件,且学习具有鲁棒性。大型扩散模型(如Stable Diffusion)可以通过ControlNet进行增强,以启用边缘图、分割图、关键点等条件输入。
输入参数:
image:输入图像(必填)。prompt:模型的文本提示(必填,默认“an astronaut on the moon, digital art”)。num_samples:样本数量,较高值可能导致内存溢出(默认“1”)。image_resolution:生成的图像分辨率(默认“512”)。low_threshold/high_threshold:Canny线检测的低/高阈值(默认100/200)。ddim_steps:步数(默认20)。scale:无分类器指导的缩放比例(默认9)。seed:随机种子。eta:控制去噪扩散过程中添加的噪声量,值越高噪声越多(默认0)。a_prompt:附加到提示的文本(默认“best quality, extremely detailed”)。n_prompt:反向提示(默认“longbody, lowres, bad anatomy...”)。detect_resolution:应用检测方法的分辨率(默认512)。
使用说明:支持通过Node.js、Python、HTTP API在Replicate上运行,也可使用Cog或Docker在本地环境运行。
目标用户与核心优势:面向AI开发者和图像生成爱好者,核心优势在于能够在保持输入图像人物姿势的前提下,通过文本提示生成全新的高质量图像,结合了Stable Diffusion的强大生成能力与ControlNet的精细姿势控制。
收费模式与价格信息:在Replicate上运行此模型每次大约花费$0.15(约6次运行/美元),实际费用因输入而异。运行在Nvidia A100 (80GB) GPU硬件上,预测通常在108秒内完成,首次API调用需冷启动模型可能耗时较长。
访问量:
9.9M
国家:
India
计价模式:
Free
评论