ImageBind
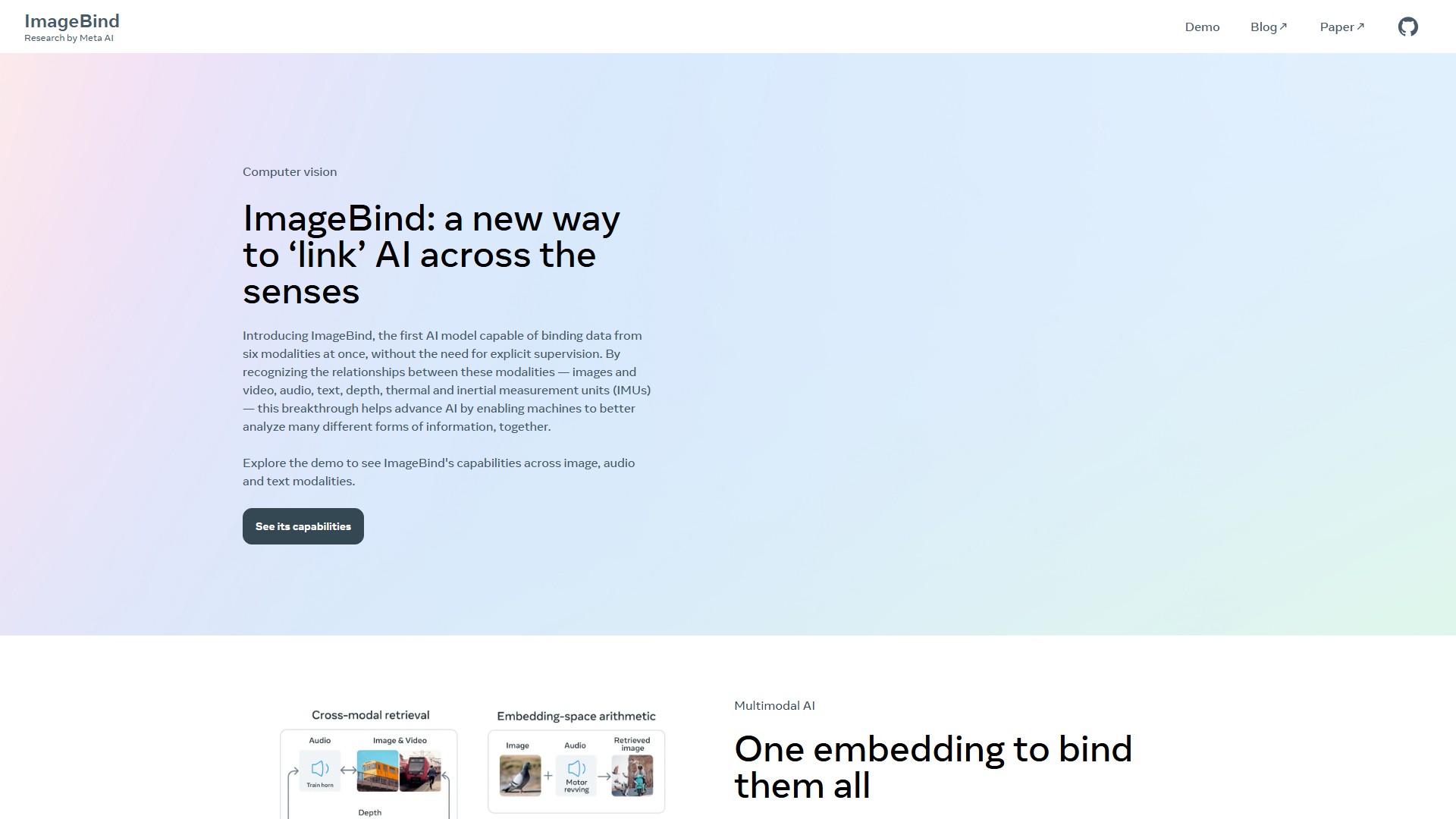
Main Features: ImageBind is the first AI model capable of binding data from six modalities (images and video, audio, text, depth, thermal, and inertial measurement units/IMUs) at once without the need for explicit supervision. By learning a single embedding space that binds multiple sensory inputs together, it can upgrade existing AI models to support input from any of the six modalities, enabling audio-based search, cross-modal search, multimodal arithmetic, and cross-modal generation.
Core Advantages: It features a breakthrough in recognizing relationships between modalities, enabling machines to better analyze many different forms of information together. The open-source ImageBind model achieves a new SOTA (state-of-the-art) performance on emergent zero-shot recognition tasks across modalities, even better than prior specialist models trained specifically for those modalities. It also enables zero-shot and few-shot recognition.
Usage Instructions: Users can explore ImageBind's capabilities across image, audio, and text modalities through the Demo page on the website. Developers can access the open-source code via GitHub for integration and development.
Other Info: The model and code are provided open-source. No pricing or fee information is mentioned on the page.
議論する